Programovanie v jazyku symbolických adries
| Obsah | Index |
Prúdové spracovanie inštrukcií (pipelining) znamená, že naraz sa v procesore spracováva viac inštrukcií. Východiskom tejto technológie je skutočnosť, že spracovanie inštrukcie možno rozložiť na (spravidla) päť jednoduchších úkonov, ktoré na seba nadväzujú:
- prenos inštrukcie z pamäti do procesora (Instruction Fetch - IF)
- dekódovanie (Instruction Decode - ID) - inštrukcia sa konvertuje do jednoduchých povelov (mikrooperácií), ktoré výkonné jednotky procesora dokážu vykonať
- výber operandu z pamäti (Data Access - DA)
- vykonanie (Execution - EX)
- zápis výsledku do pamäti (Write Back - WB)
Každý úkon sa vykonáva v samostatnom funkčnom bloku, prípadne sa rozloží na ešte jednoduchšie operácie a vykonáva sa v niekoľkých funkčných blokoch. Funkčný blok (functional unit) je skupina logických obvodov, ktoré vykonávajú spoločnú prácu (napr. aritmeticko-logická jednotka). Pri klasickom spracovaní údajov by sa ďalšia inštrukcia začala spracovávať až po ukončení spracovania predchádzajúcej inštrukcie. Pri takomto spôsobe práce by funkčné bloky väčšinu času zaháľali a čakali na príchod ďalších údajov. Prúdové spracovanie údajov prebieha tak, že funkčné bloky sú zoradené logicky za sebou a tvoria kanál (pipe). Akonáhle spracovanie inštrukcie postúpi z prvého stupňa (funkčného bloku) do druhého, môže prísť ďalšia inštrukcia a vstúpiť do prvej fázy svojho spracovania. Tým sa dosiahne, že až na niekoľko výnimiek sa v každom hodinovom cykle ukončí jedna inštrukcia.
Niekedy sa môže narušiť plynulosť inštrukčného toku. Ide najmä o tieto situácie (označujú sa pojmom pipeline hazards):
-
dátová závislosť - vyskytuje sa, keď zdrojový operand jednej inštrukcie je
cieľovým operandom predchádzajúcej inštrukcie. Napr.
ak za sebou nasledujú inštrukcie
mov ebx,Adresa; ulož adresu do registra ebx
musí druhá inštrukcia čakať, kým sa v prvej inštrukcii naplní register EBX.
mov eax,[ebx]; skopíruj do registra eax obsah dvojslova, ktorého adresa je v registri ebx
Hoci procesor má logiku, ktorou sa snaží dátovú závislosť eliminovať, môžeme sa o to pokúsiť aj na úrovni nášho programu tým, že medzi dátovo závislé inštrukcie vložíme inštrukcie nezávislé. Napr. ak v uvedenom príklade bola postupnosť inštrukcií takáto:mov ecx,2000
môžeme prehodiť prvú a druhú inštrukciu:
mov ebx,Adresa; ulož adresu do registra ebx
mov eax,[ebx]; skopíruj do registra eax obsah dvojslova, ktorého adresa je v registri ebxmov ebx,Adresa; ulož adresu do registra ebx
mov ecx,2000
mov eax,[ebx]; skopíruj do registra eax obsah dvojslova, ktorého adresa je v registri ebx - konflikty riadenia - vyskytujú sa pri inštrukciách vetvenia, kedy sa môže prerušiť sekvenčné vykonávanie inštrukcií a preniesť riadenie na vzdialené miesto v programe. Vetviaca inštrukcia obsahuje nejakú logickú podmienku, ktorá sa vyhodnotí a vykoná sa skok na návestie, ak je podmienka splnená. Do inštrukčného kanálu (pipeline) však prichádzajú inštrukcie ešte predtým, ako sa podmienka vyhodnotí. Ak sa v okamihu vyhodnotenia podmienky zistí, že pipeline obsahuje inštrukcie z tej vetvy programu, ktorá sa nebude vykonávať, je potrebné pipeline vyprázdniť a načítať inštrukcie zo správnej vetvy. Ak vieme už pri programovaní určiť, ktorá vetva programu je pravdepodobnejšia, umiestnime ju za vetviacu inštrukciu a podmienku konštruujeme tak, aby sa skákalo do menej pravdepodobnej vetvy.
- štrukturálne konflikty - vyskytujú sa v prípade, že viac inštrukcií súčasne požaduje rovnaký prostriedok procesora, napr. súčasný prístup ku cache pamäti. V boji o prostriedok dostáva prednosť tá inštrukcia, ktorá je viac rozpracovaná (je dlhšie v pipeline), zatiaľčo druhá inštrukcia (a všetky, ktoré za ňou nasledujú v pipeline) musí čakať, kým sa prostriedok uvoľní. Najčastejšie dochádza k sporom o zbernicu, či už internú alebo externú. Preto sa pri programovaní snažíme obmedziť prístup do pamäti, čiže vyhýbame sa používaniu pamäťových operandov a radšej pracujeme s registrami procesora.
Procesory s touto architektúrou uviedol Intel na trh v polovici roku 2013. Je to zatiaľ posledná 64-bitová architektúra (adresa aj univerzálne registre sú 64-bitové). Jadro procesora Haswell tvoria tieto základné bloky:
- cache pamäť niekoľkých úrovní (L2 Cache, L1 Data Cache, L1 Instruction Cache, L0 Instruction Cache)
- jednotka pre predpovedanie skokov (Branch Prediction)
- jednotka pre výber inštrukcií (Instruction Fetch Unit)
- dekódery
- jednotka pre spracovanie inštrukcií mimo poradia (Out-of-Order Unit)
- výkonný podsystém (Execution Units)
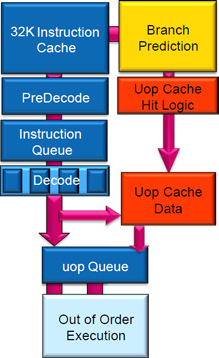
Obr. 2. Schéma architektúry Haswell
Cache pamäť druhej úrovne obsahuje podobne ako hlavná pamäť inštrukcie aj dáta.
Výberová jednotka (Instruction Fetch Unit) prináša inštrukcie z cache pamäti druhej úrovne (L2 Cache) do inštrukčnej cache pamäti prvej úrovne (L1 Instruction Cache), ktorá má kratšiu prístupovú dobu. Pred výberom inštrukcie sa vykonáva predpovedanie skokov (Branch Prediction), o ktorom bude reč v nasledujúcej kapitole. Z L1 Instruction Cache sa naraz prenesie 16B do buffra preddekódera, ktorý rozpozná v bloku inštrukcií hranice inštrukcie, lebo inštrukcie v strojovom kóde môžu mať rôznu dĺžku (1 až 17 bajtov). Preddekóder tiež rozpozná prefixy, ktorými sa napríklad mení implicitná veľkosť operandu. Ďalej tok inštrukcií smeruje do štyroch dekóderov, ktoré rozložia inštrukciu na mikrooperácie a uložia ich do L0 Instruction Cache (na obr. 2 označená ako micro-op Queue). L0 Instruction Cache predstavuje "zásobník" dekódovaných inštrukcií, ktoré sú pripravené na vykonanie.
Jednotka pre spracovanie inštrukcií mimo poradia (Out-of-Order Unit) pripravuje inštrukcie na vykonanie. Preberá mikrooperácie zo "zásobníka" a prehádže ich tak, aby sa odstránila dátová závislosť a aby výkonné jednotky boli čo najviac využité. Ukladacia jednotka (Retirement Logic) má za úlohu znovu usporiadať inštrukcie vykonané mimo poradia späť do pôvodného poradia podľa programu. Ukladacia jednotka dostáva informáciu o ukončení vykonávania inštrukcie z výkonných jednotiek a ukladá ich výsledky tak, aby sa zachoval stav definovaný programom. To znamená, že výsledky sa do pamäti (L1 dátovej cache) neuložia dovtedy, kým nie sú dokončené predchádzajúce operácie. Podobne interné prerušenie (výnimka) sa spracuje len vtedy, keď inštrukcia, ktorá ho spôsobila, je najstaršou spomedzi nedokončených inštrukcií.
Výkonný podsystém (Execution Units) pozostáva z viacerých výkonných jednotiek, ktoré môžu pracovať súčasne. (Architektúra s viacerými výkonnými jednotkami sa nazýva superskalárna architektúra.) V mikroarchitektúre Haswell sú tieto výkonné jednotky:
- výpočtové výkonné jednotky
- 4 aritmeticko-logické jednotky (Arithmetic and Logic Unit - ALU) – vykonávajú operácie s celými číslami
- 3 jednotky pre spracovanie čísiel v pohyblivej rádovej čiarke (Floating Point Unit - FPU)
- 3 jednotky pre celočíselné vektorové operácie v technológii SIMD
- pamäťové výkonné jednotky
- jednotka pre ukladanie dát do L1 dátovej cache
- 3 jednotky pre výpočet adresy

Architektúra moderných procesorov
Služby operačného systému MS-DOS
Služby operačného systému Windows 95/98/NT/XP
 Architektúra moderných procesorov | Dynamické spracovanie inštrukcií Architektúra moderných procesorov | Dynamické spracovanie inštrukcií |
Otázky a pripomienky môžete poslať autorke.
Naposledy upravené 25.9.2014.